How ChatGPT Works Step by Step
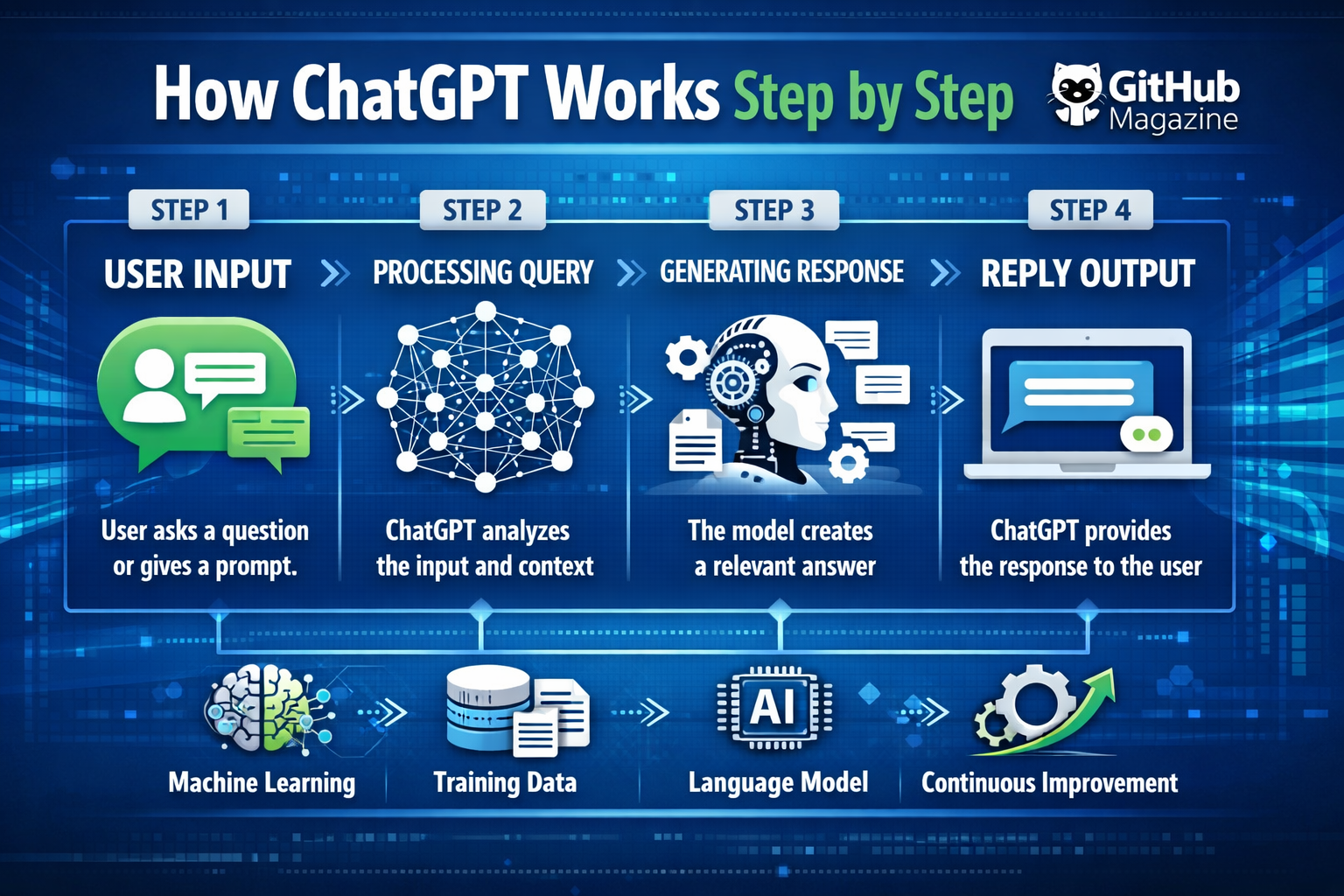
I like to think of ChatGPT as a system that predicts language rather than understands it in the human sense. When someone types a question, the model begins working immediately, converting words into structured data, analyzing patterns, and generating a response step by step. Within moments, it transforms text into tokens, maps relationships between words, and predicts what should come next.
At its core, ChatGPT operates using a transformer-based neural network. This architecture allows it to process entire sentences at once rather than word by word. The result is a system that can maintain context, generate coherent responses, and simulate conversation with surprising fluency. It does not think, reason, or feel, but it does calculate probabilities with remarkable precision.
The process may seem instantaneous, yet it unfolds through a series of carefully designed stages. Each stage builds upon the previous one, turning raw input into structured understanding and eventually into a generated reply. By examining these steps in detail, the complexity behind what appears to be a simple chat interface becomes much clearer.
Step 1: Input Processing and Tokenization
The process begins the moment a user enters text. I observe that the system does not interpret language directly. Instead, it breaks the input into tokens, which are smaller units such as words, subwords, or punctuation marks. This step is essential because computers cannot process language in its natural form.
Tokenization standardizes the input and ensures that every piece of text can be handled consistently. A single sentence might be divided into dozens of tokens depending on its structure. Each token is then assigned a numerical value, making it possible for the system to process language mathematically.
This transformation from words to numbers is fundamental. Without it, the model would not be able to analyze patterns or make predictions. Tokenization also allows the system to handle different languages and writing styles with relative ease, creating a flexible foundation for all further processing.
Step 2: Embedding and Context Encoding
Once tokenization is complete, the tokens are converted into embeddings. I see embeddings as numerical representations that capture the meaning of each token in relation to others. These are not dictionary definitions but learned relationships based on patterns in data.
At this stage, context becomes crucial. Words rarely have fixed meanings, and their interpretation depends on surrounding words. The system uses positional encoding to preserve the order of tokens, ensuring that meaning is not lost when processing sentences.
| Component | Role in the Process | Impact on Output |
|---|---|---|
| Tokenization | Splits text into units | Enables processing |
| Embeddings | Converts tokens to meaning vectors | Adds semantic depth |
| Positional Encoding | Maintains sequence order | Preserves context |
This combination allows the model to recognize relationships between words, even when they are far apart in a sentence. It creates a structured representation of language that can be analyzed efficiently.
Step 3: Transformer and Attention Mechanism
The transformer is the core engine of ChatGPT. I often describe it as a system that looks at all parts of a sentence at once and decides which words matter most. This is achieved through the attention mechanism.
Attention allows the model to assign importance to different tokens. For example, when interpreting a sentence, it can determine which words are related and how they influence each other. This ability is what makes the model capable of handling complex language structures.
The transformer is built in layers, and each layer refines the understanding of the input. Early layers capture basic relationships, while deeper layers identify more abstract patterns. This layered processing enables the model to build a detailed representation of the text before generating a response.
Step 4: Training on Large-Scale Data
The capabilities of ChatGPT come from its training. I recognize that the model does not learn during conversations but is pre-trained on massive datasets containing diverse text sources. This includes books, articles, and other written material.
During training, the model repeatedly predicts the next token in a sequence. By doing this billions of times, it learns grammar, facts, and patterns of reasoning. Over time, it becomes highly effective at generating coherent text.
| Training Stage | Purpose | Result |
|---|---|---|
| Pre-training | Learn general language patterns | Broad knowledge base |
| Fine-tuning | Adjust behavior with curated data | Improved accuracy |
| Reinforcement Phase | Align responses with human preferences | Better usability |
This process does not create understanding in a human sense but builds a statistical model of language that can produce meaningful outputs.
Step 5: Prompt Interpretation
When a user submits a query, the model analyzes it to determine intent. I notice that it relies on patterns rather than reasoning. It compares the input with examples it has seen during training and identifies the most relevant patterns.
The structure of the prompt plays a significant role. Clear and specific inputs lead to more accurate outputs, while vague prompts may produce broader responses. The system also considers context from previous messages when generating replies.
This step is where the interaction begins to feel intelligent. The model adapts its output based on the structure and content of the input, creating the illusion of understanding.
Step 6: Response Generation
Response generation happens one token at a time. I find this step particularly fascinating because the model does not generate entire sentences at once. Instead, it predicts each token sequentially.
The process works like this:
First, the model predicts the most likely next token based on the input.
Then, it adds that token to the sequence.
Finally, it uses the updated sequence to predict the next token.
This continues until the response is complete. Because the process is probabilistic, the same input can produce different outputs at different times. Parameters such as randomness influence how creative or predictable the response will be.
Step 7: Output Filtering and Safety Systems
Before the response is delivered, it passes through safety systems. I see this as a necessary layer that ensures outputs remain appropriate and aligned with guidelines.
These systems filter out harmful or biased content and enforce constraints on what the model can generate. They are continuously updated to address new challenges and improve reliability.
This step ensures that the final output is not only coherent but also responsible.
Step 8: Continuous Improvement
ChatGPT evolves through updates rather than real-time learning. I understand that developers periodically improve the model using new data and techniques. These updates enhance performance, accuracy, and safety.
Improvements may include better training datasets, refined algorithms, and stronger alignment methods. Over time, these changes lead to more capable and reliable systems.
Expert Perspectives
“Large language models function by predicting probabilities, not by understanding meaning,” one leading AI researcher explains, highlighting the statistical nature of these systems.
Another expert notes, “Scaling data and computation has been the primary driver behind recent advancements in AI.”
A third perspective emphasizes, “The transformer architecture fundamentally changed how machines process language, enabling parallel analysis of entire sentences.”
These viewpoints reinforce the idea that ChatGPT is a product of engineering and data rather than cognition.
Key Takeaways
- ChatGPT converts text into tokens for processing
- Embeddings provide numerical representations of meaning
- Transformers analyze relationships using attention mechanisms
- Training involves predicting the next word across large datasets
- Responses are generated sequentially, one token at a time
- Safety systems filter outputs before delivery
- Continuous updates improve performance over time
Conclusion
I view ChatGPT as a system that mirrors language patterns rather than truly understanding them. Its strength lies in its ability to process vast amounts of data and generate responses that feel natural and coherent. Each step, from tokenization to response generation, contributes to this capability.
The technology represents a shift in how machines interact with humans. Instead of following rigid instructions, it adapts to patterns and produces flexible outputs. This makes it useful across many applications, from education to communication.
At the same time, its limitations are important to recognize. It does not possess awareness or intent, and its outputs depend entirely on the data it was trained on. Understanding how it works step by step provides a clearer perspective on both its potential and its boundaries.
FAQs
What is the main function of ChatGPT?
It predicts and generates text based on patterns learned during training.
Does ChatGPT learn from conversations?
No, it does not learn in real time but improves through periodic updates.
Why does ChatGPT sometimes give different answers?
Because it generates responses probabilistically, leading to variation.
What is a transformer model?
It is a neural network architecture that processes language using attention mechanisms.
Is ChatGPT always accurate?
No, it can produce incorrect or outdated information.